Agent
整体架构
下图即是项目的整体架构
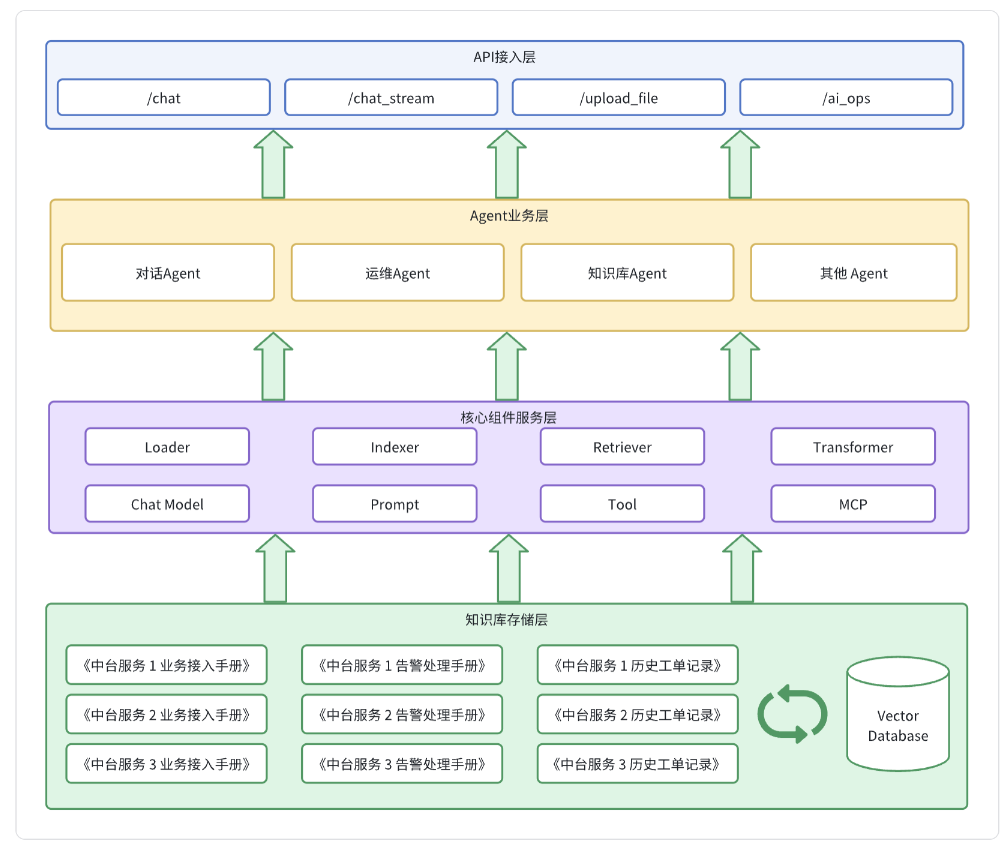
可以分为
- 接入层
- 业务层
- 服务层
- 存储层
知识库Agent
本质上是RAG的过程,在对话Agent和运维Agent里,基本都会使用到RAG
核心流程
RAG的整体流程分为两部分:
提问前(数据准备):分片->embedding ->存储
提问后(回答生成):召回->重排->生成
提问前链路(数据准备)
- 分片:将原始文档(如业务告警处理手册)切割为多个语义完整的片段。
- 索引:
。用Embedding模型将每个片段转为向量。
。将片段文本和向量存入向量数据库。 - 完成后,知识库即构建完毕,等待用户提问。
提问后链路(回答生成)
-
召回:用户问题->Embedding模型->向量->向量数据库->Top10相关片段。
-
重排: Top10片段->Cross Encoder模型->Top3最相关片段。
-
生成:Top3片段+用户问题->大模型->最终答案。
项目细节
读取文件
我们直接传入文件路径path,调用Files.readString读取文件内容到内存
文件分块
其他的文件可以考虑使用minerU将pdf文件这些提取信息
1.第一层按照Markdown的标题#切分,将文档按照标题分割成多个章节Section
2.第二层对每个章节进行分配,如果章节小于MaxSize,则直接将这个章节作为一个分配。
3.如果章节大于MaxSize,则对段落边界进行切分
4.对于对段落边界进行切分的地方,还会根据Overlap,实现段落间内容重叠,来保持段落之间的上下文语义连贯
文件索引(向量化和存储到数据库)
-
首先对所有分片进行向量化,获取向量数组
-
构造符合milvus表记录的结构体。id、content、vector、metadata
-
构造完记录后,插入到数据库中
召回
我们之前是将文档存储到了Milvus向量数据库里面,所以召回的时候也是从这个数据库去查询。
- 将查询文本向量化
- 相似度查询(余弦相似度)
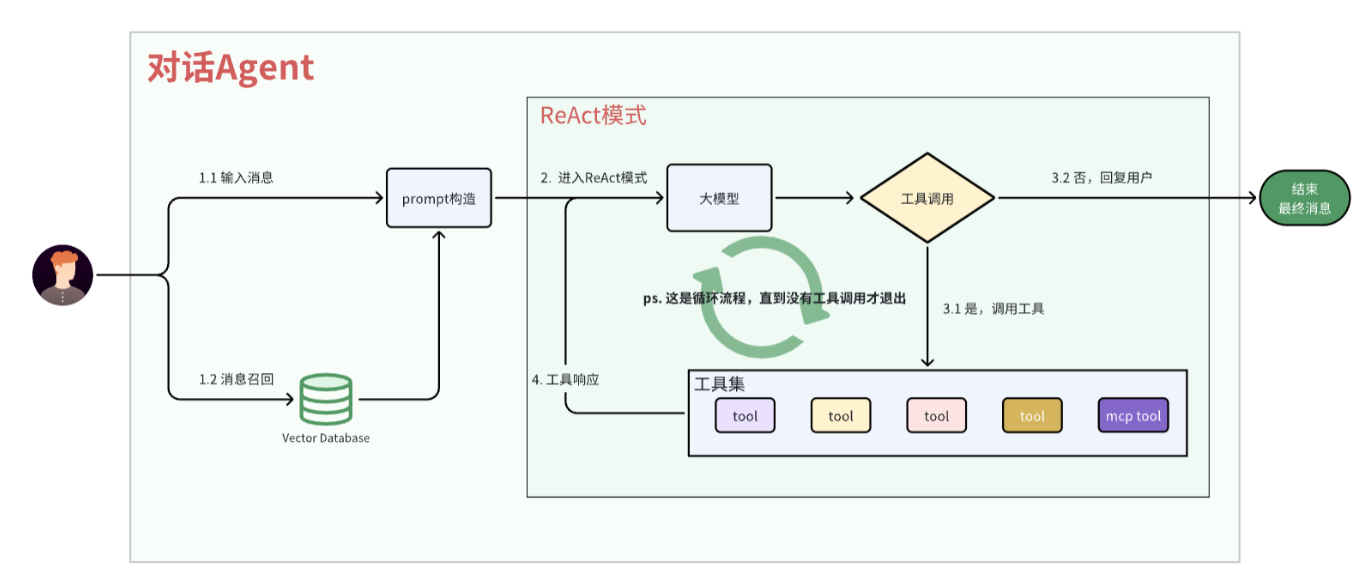
对话Agent
使用ReAct模式,ReAct=Reasoning(推理)+ Acting(行动),核心是让 AI 像人一样边想边做、边做边调整,通过思考->行动->观察->再思考来解决问题。
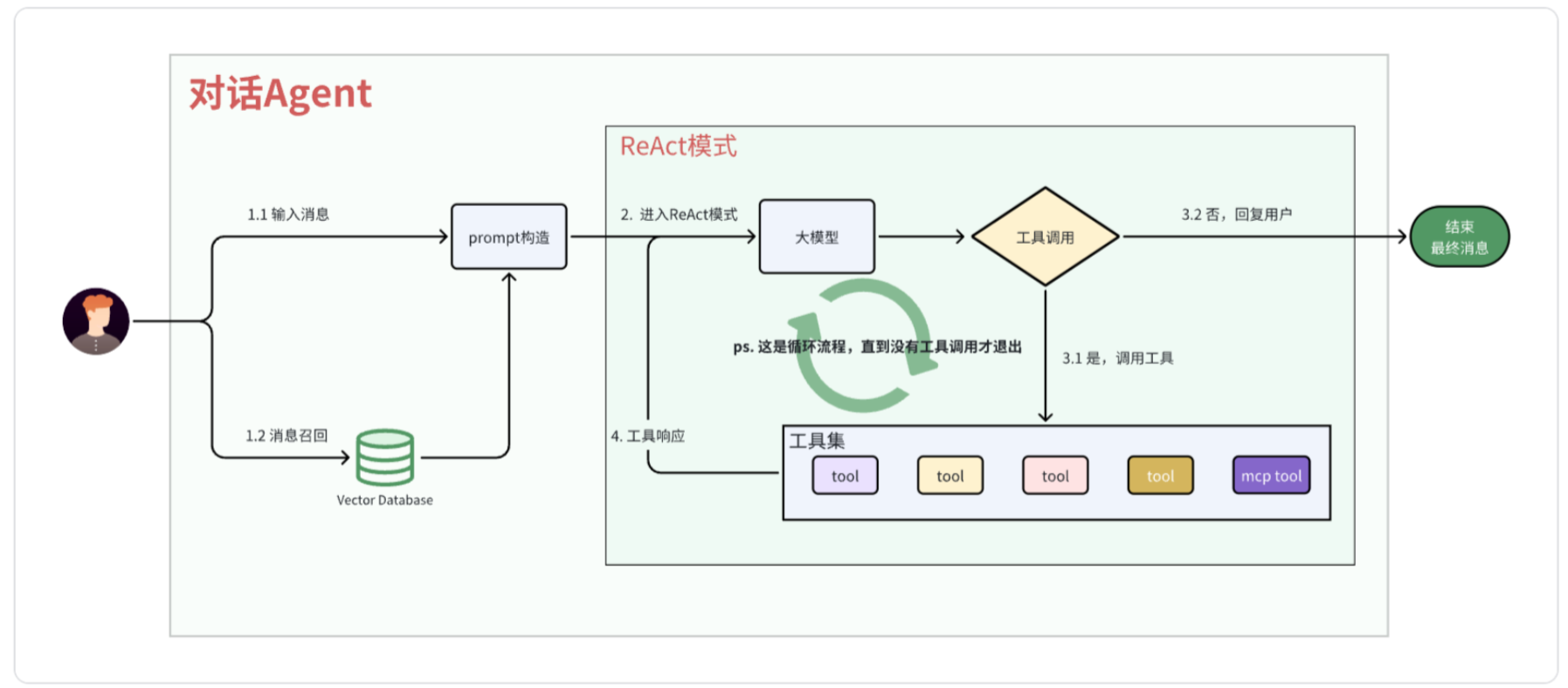
流程梳理
对话Agent的核心目标是结合外部知识(RAG召回)与工具调用能力(ReAct模式),解决复杂问题。
整体流程可概括为:
- 用户输入->embedding->向量数据库召回
- 构建带上下文(召回的内容)的prompt
- ReAct模式多轮交互
- 最终输出答案
不足的地方
记忆存储,当前只是使用ConcurrentHashMap进行存储的,没有长期进行存储,可以升级为长期记忆存储(向量书库)
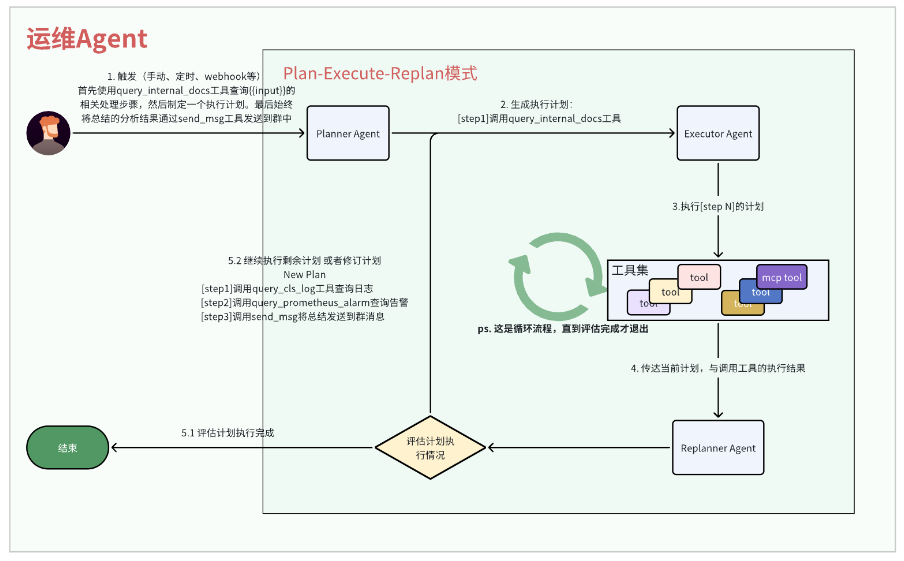
运维Agent
运维Agent的核心目标是将运维人员的告警处理经验转化为自动化流程。使用Plan-Execute-Replan的设计模式,即先规划-再执行,再重新规划
与ReAct的核心区别:先规划vs边想边做
| 对比维度 | Plan-Execute-Replan | ReAct |
|---|---|---|
| 核心思路 | 结构化计划(先拆步骤,按计划执行) | 实时决策(边想边做,无固定步骤) |
| 适用场景 | 复杂流程类任务(如报告生成、项目管理) | 灵活探索类任务(如问答、解谜) |
| 步骤特点 | 提前规划步骤序列(可动态调整) | 动态生成下一步(无预设顺序) |
| 优势 | 任务进度可控、步骤清晰有序 | 灵活应对未知情况 |
运维Agent的自动化能力源于三方面协同:
结构化规划:Planner将模糊的运维经验转化为可执行步骤,降低复杂告警的处理门槛
工具化执行:Executor集成监控/日志系统,替代人工重复操作,提升响应速度
动态的调整:Replanner根据实时结果修正计划,适配下游发版/临时抖动等不确定性场景
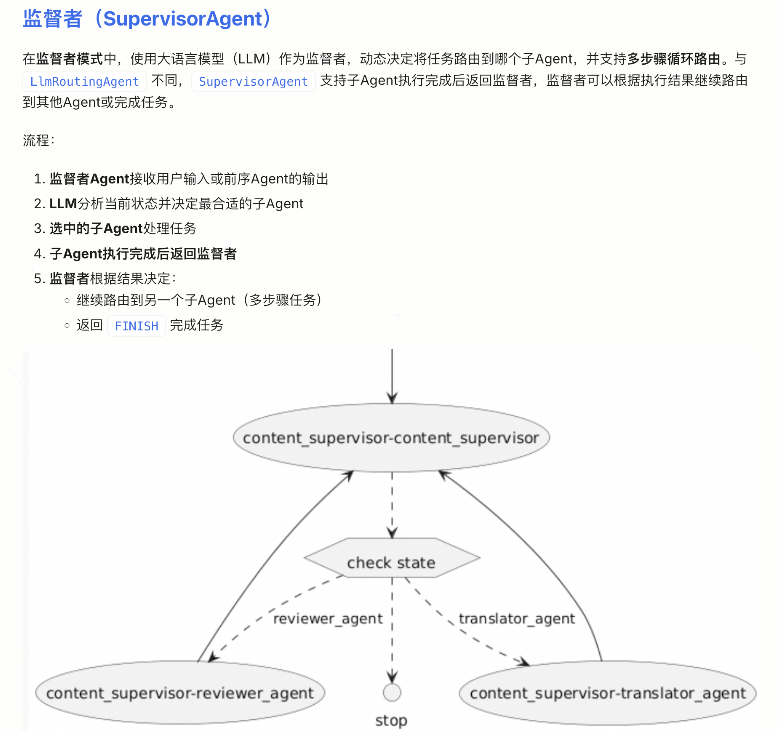
使用框架的SupervisorAgent能力,可以自动的帮助我们管理PlanAgent和ExecutorAgent之间的执行扭转,其核心就是流程控制,与Plan对象在整个流程中的传递而已。
面试相关

cusor
好用的skills:
- pptx : 自动生成ppt
- skill-creator: AI 根据你的需求,自己写一个新的 Skill
openclaw
- 协议层:MCP 的标准化
OpenClaw 的爆火证明了 MCP(Model Context Protocol) 是 Agent 规模化的基石。
- 理解点:它不再为每个工具手写 JSON Schema,而是通过标准协议实现“即插即用”的环境感知。
- 面试谈资:如何利用协议统一管理本地文件、数据库和第三方 API 的上下文。
- 规划层:从 Chain 到循环(Loop)
它打破了简单的 ReAct 线性逻辑,引入了自我修正(Self-Reflection)。
- 理解点:任务失败后,Agent 会进入“观察-反思-重试”的闭环,而不是报错退出。
- 面试谈资:如何处理长序列任务中的幻觉累积和状态恢复(Checkpointing)。
- 执行层:Computer Use 与沙箱
它是目前 VLM(视觉大模型) 控制 GUI 的标配实现。
- 核心挑战:安全。必须讨论 Docker/Firecracker 等隔离技术,防止 Agent 误删系统文件。
- 面试谈资:如何平衡视觉解析的“高延迟”与操作指令的“实时性”。
- 工程化:成本与可靠性
- Token 优化:Agent 是“Token 吞噬者”,OpenClaw 采用了动态上下文裁剪。
- 评估体系(Evals):如何量化 Agent 的成功率?面试官看重你是否拥有一套基于 Task Success Rate 的自动化测试方案。
openclaw的记忆机制:三层,
会话记忆:agents/main/sessions/f4fc3f5.json,json格式,保留了 Agent 的思考过程(CoT)、工具调用(Tool Calls)、API 耗时以及系统元数据
长期记忆:workspace/memory.md 用户喜好,重要的事实
日常记忆:workspace/memory/2026-03-27.md 日常记忆,只追加
agent的组成部分
大语言模型,规划模块,记忆模块,工具集
简单介绍一下你设计的几个Agent
在项目里一共实现了2个Agent,分别是对话Agent和运维Agent,同时还做了RAG。
知识库的核心目标是作为团队文档管理和AI应用的基础设施,通过自动化流程,将我们日常积累的文档
(告警处理手册、技术方案、错误码文档),转化为可被AI高效检索的向量,为后续的RAG提供了高质量的向量数据支撑。举个最常见的例子,当我们想根据一个模糊的回忆找文档的时候,可以根据模糊的提问快速检索到对应文档,不再需要再嵌套目录里面一个一个翻了。
-
对话Agent本质上是一个基于大模型+知识库构造的ReAct模式智能交互系统。你可以把它看作是一个能够像真人一样理解问题、调用知识库检索并给出精准回答的小助手。它最重要的使命就是帮助团队挡掉高频的重复咨询,加速问题解决,从而提高整体的工作效率。
- 输入:用户对话
-
运维Agent是为了解决值班排查问题的痛点而做一个Multi-Agent(多智能体)的。运维Agent主要是使用了Plan-Execute-Replan设计模式,有Plan-Execute-Replan这三个agent,运维Agent可以通过调用各平台的API,实现跨系统联动,一站式完成排查。可以自动从告警中提取接口名和时间范围,查询日志、查询历史工单、查询监控、查询告警处理手册,将所有信息汇总成一份结构化的故障排查报告。
- 输入:告警信息(alertname、description) + 召回的处理文档 (告警触发) ;输出:结构化计划(SON格式),包含步骤描述、工具调用参数、预期结果
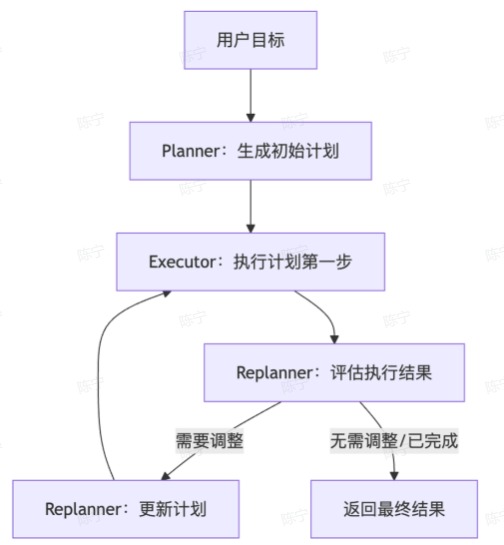
agent的流程
ReAct和Plan-Execute-Replan有什么区别?
- ReAct适合边想边做,没有固定步骤
- Plan-Execute-Replan适合处理复杂任务,先拆解步骤,再执行,根据执行结果判断要不要修改计划
- 所以在我的项目中,对话场景用ReAct,因为用户问题灵活,需实时决策。它的职责是处理开放式的,多轮的业务咨询,比如回答某个API怎么用,特点是灵活,能根据对话历史动态决定下一步做什么,但执行链条不会预设得特别长。
- 运维场景用Plan-Execute-Replan,比如专门处理告警。它的职责是接受一个明确目标,然后制定一个可能包含多步骤的排查计划,并严格按计划调用各工具执行。
- 它们底层共享同一套工具集和知识库,但工作模式和目标不同
| 对比维度 | Plan-Execute-Replan | ReAct |
|---|---|---|
| 核心思路 | 先拆步骤,按计划执行,动态调整 | 边想边做,每步临场决策 |
| 有没有全局计划 | 有,一开始就生成完整计划 | 没有,走一步看一步 |
| 适合什么场景 | 多步骤、流程化的复杂任务(运维排查、报告生成) | 灵活探索类任务(开放问答、信息检索) |
| 任务进度 | 可追踪,知道执行到第几步了 | 不太好追踪,因为没有预设步骤 |
| 应对变化 | 通过Replan机制调整计划 | 天然灵活,每步都能变方向 |
| Agent数量 | Multi-Agent协作 (Planner + Executor + Replanner) | 通常是单Agent完成所有事 |
你的工具集有哪些Tool,分别有什么功能?
- 其实设计tool就是要思考Agent需要哪些功能
- 首先想到的是知识库召回工具,从向量数据库中召回最相关的3份片段
- 然后是日志查询工具,日志查询是通过腾讯云日志平台的MCP实现的,他们的MCP支持用自然语言查询日志
- 还有告警查询工具,对接监控系统的/alerts接口,直接获取当前活跃告警信息
- 其实在测试过程中,我还发现大模型不能精准知道当前时刻的时间,所以还编写了一个时间查询工具,为Agent提供实时时间信息,辅助告警持续时长的计算
- 最后还有一个联网查询工具,集成外部搜索引擎,让大模型也有搜谷歌的能力
agent怎么知道调用哪个工具
核心机制:语义意图对齐 (Semantic Intent Alignment)
大模型并不是通过“If-Else”代码来选工具的,而是通过注意力机制(Attention)。
- 注入上下文: 当我们把工具列表发给模型时,每个工具都有详细的
description。模型会将你的提问(Query)与这些描述进行向量空间上的匹配。 - 语义匹配: 比如用户说“帮我重启一下 A 服务”。模型会在上下文里搜寻关键词,发现某个工具的描述里写着“本工具用于对指定服务执行重启操作”。由于语义高度相关,模型在输出时,概率最高的方向就会指向这个工具的 ID。
技术手段:Native Function Calling (原生函数调用)
目前最主流的方式是利用模型厂商提供的 Function Calling API(如 OpenAI 或阿里通义)。
- Schema 约束: 我们将工具定义为标准的 JSON Schema。它不仅包含描述,还包含了参数的类型、必填项和枚举值。
- 模型输出: 模型一旦决定用某个工具,它不会直接返回一句话,而是返回一个结构化的 JSON。
- 示例: `{“tool_name”: “restart_service”, “arguments”: {“service_id”: “A”}}
复杂场景下的“路由 Agent” (Hierarchical Routing)
在我们的 WAgent 项目中,如果工具太多,我们会加一个“门卫(Router)”。
- 一级路由: 先由一个轻量级模型判断这属于“查询类”、“修改类”还是“分析类”。
- 二级加载: 根据分类,只把该类别下的 5 个工具塞给模型。
- 精准选择: 模型在缩小的范围内进行最终选择。这能极大地降低“选错工具”的概率。
向量数据库的选型对比
| 维度 | Milvus | Pinecone | PGVector(PostgreSQL插件) | Chroma | Qdrant |
|---|---|---|---|---|---|
| 部署方式 | 私有化/云端 (Docker/K8s) | 仅 SaaS | 插件集成 | 无原生持久化存储,依赖外部数据库 | 单机稍弱,分布式提升有限 |
| 开源 | 是 | 否 | 是 | Python 环境 | |
| 扩展性 | 极强 (分布式) | 强 (自动) | 弱 (单机垂直) | ||
| 索引算法 | 全面 (HNSW, IVF, etc.) | 闭源优化 | 较少 (HNSW, IVFFlat) | 高并发场景下吞吐量有限 | |
| 适用场景 | 大规模、私有化、复杂运维 | 快速原型、海外业务 | 中小规模、强事务关联 | 轻量级,API 简单 | 分布式性能不如 Milvus |
文档更新
-
首先在数据库中维护了一张文档元数据表,记录每个文档的路径、最后修改时间、索引状态等信
息。 -
当有新文档上传或文档更新时,系统会比对最后修改时间,识别出需要重新索引的文档。
-
对于需要重新索引的文档,会先从向量数据库中删除该文档的旧的向量数据,然后重新执行加
载、分块、向量化、存储的流程。 -
这个过程是异步的,不会影响正常的查询服务。用户上传文档后会立即返回,后台会有一个定时
任务或消息队列来处理索引任务。
你的项目用的是什么模型?
- 向量模型我使用的是阿里的text-embedding-v4
- 语言模型我使用的是qwen3-max(总参数量1万亿。激活参数220亿)
因为是在国内使用,公司使用,所以选择模型最好还是选择国内的。
搭建RAG时选择合适的embedding模型很重要,Huggingface有一个MTEB(Massive Multilingual Text
EmbeddingBenchmark)评测标准是一个业界比较公认的标准。
打开MTEB的官网,阿里的模型就排在第三,所以embedding就选择使用阿里的模型了
rag流程
提问前(数据准备):分片→Embedding→存储
提问后(回答生成):召回→重排→生成
召回与重排的区别是什么?
- 召回:快速捞出相关片段
- 将用户问题通过Embedding模型转化为向量。
- 用向量相似度算法计算问题向量与数据库中所有片段向量的相似度,挑出TopN(如10个)最相关的片段。
- 特点:速度快、成本低,但准确率有限,适合初步筛选-
- 重排:给片段排优先级
- 使用专门计算文本对相似度的模型,逐对计算用户问题与每个召回片段的语义相关性。
- 从10个片段中选出TopK(如3个)最相关的片段。
- 为什么不直接召回3个?召回用向量相似度(快但准度低),重排用CrossEncoder模型(慢但准度高),二者结合实现先广撒网再精挑细选,效果优于一步到位。
你的系统如何避免大模型产生幻觉?
大模型幻觉是AI应用中最需要关注的问题,我主要从四个方面来控制:
- 第一是强约束的Prompt设计,在系统Prompt中明确要求:"严格按照文档内容回答,不允许使用文档外的任何信息”、”如果不知道答案,明确说不知道,不要编造”。这样可以从源头上约束大模型的输出。
- 第二是RAG增强,通过检索相关文档片段,给大模型提供可靠的事实依据。在对话Agent中,我会把召回的文档片段明确标记为”参考文档”,让大模型基于这些文档来回答。
- 第三是相似度阈值过滤,我设置了0.8的高阈值。如果召回的文档相似度低于这个值,说明知识库中没有相关信息,这时会直接告诉用户”知识库中暂无相关信息”,而不是让大模型凭空猜测。
- 第四是人工反馈闭环,我在系统中加入了功能。用户如果觉得回答不准确,可以点击反馈,后台会记录logid并通知到群里。我会人工分析原因,如果是文档缺失就补充文档,如果是prompt问题就优化prompt。
通过这四层防护,大部分情况下都能给出可靠的答案
大模型怎么发现tools的
- 直接在代码里把工具列表发给大模型。在
tools数组里写好read_log、restart_service的描述(StringAI 可以对tool统一管理,在tools上加上注解就好了) - mcp握手,当 Agent 启动或连接到一个新的 MCP Server 时,MCP Server 会返回一个 JSON 列表,包含工具的名称、详细描述、参数 Schema
为什么选择 MCP 协议?相比 Function Calling 的优势?
不同LLM厂商返回的工具调用指令格式各不相同,MCP(Anthropic )创建了一个标准化的中间层,像"通用适配器"一样统一LLM与外部工具调用的交互方式。实现编写一次工具,可以在各个模型之间运行
它把复杂的连接逻辑拆解成了三个角色:
- MCP Host (客户端): 比如 Claude Desktop、IDE(Cursor/VS Code),或者我们正在做的 WAgent 后端。它是发起请求的一方。
- MCP Server (服务端): 这是一个轻量级的程序,它负责暴露特定的功能。比如一个“MySQL MCP Server”,它知道怎么查数据库,并将结果按 MCP 格式返回。
- Local/Remote Resources (资源): 实际的数据(数据库、本地文件、API)。
为什么它比传统的 Function Calling 强?
在 WAgent 项目里,如果你直接用传统的工具调用,你需要给模型写很长的 Description,还得处理各种 API 鉴权和格式转换。而 MCP 带来了以下变革:
| 维度 | 传统方式 (Function Calling) | MCP 模式 |
|---|---|---|
| 复用性(解耦) | 针对每个模型(GPT, Claude, DeepSeek)都要写适配代码。 | 一次编写,到处运行。一个 MCP Server 可以被任何支持该协议的客户端调用。 |
| 生态系统 | 需要自己造轮子。 | 社区已经有现成的 Server(GitHub, Google Drive, Slack, Postgres),直接插拔使用。 |
| 安全性 | 模型直接接触 API Key,风险高。 | 逻辑在本地 Server 运行,模型只下达指令,不接触敏感凭证。 |
我们可以把MCP想象成电脑的USB-C接口,键盘、U盘、显示器就是不同的MCPServer,它们提供各自独特的功能。电脑就是Agent,它作为MCPClient,通过统一的USB-C接口(即MCP协议)来连接和使用所有外设(MCP Server)
mcp和skills的区别
mcp connects model to data , skills teach model what to do with that data
即核心区别就是mcp是给大模型提供数据的,比如昨天的销售记录,而skills是教大模型怎么处理这些数据,是一份说明文档
skills组成 :md,script,资源文件
图编排(Graph Orchestration)的实现与痛点
我们在 WAgent 中使用了基于 图 (Graph) 的编排逻辑(类似于 Java 版的 LangGraph 思路),替代了传统的线性 Chain。
- 如何实现: 我们将不同的 Agent(Knowledge Agent, Chat Agent, Ops Agent)定义为 Node(节点),将业务逻辑判断定义为 Edge(边)。利用图驱动引擎,根据前一个节点的输出来决定下一个流向。
- 解决的痛点:
- 解决“循环”问题: 运维任务经常需要循环(比如:检查状态 -> 未就绪 -> 等待 -> 再检查)。线性 Chain 无法优雅处理循环,而图天然支持环路。
- 逻辑可视化: 复杂的运维流程(如故障排查、自动扩容)逻辑极深。图编排让我们可以将流程可视化,极大地降低了调试和后期维护的复杂度。
- 细粒度控制: 我们可以针对图中的某个特定节点(如“高危操作确认”)强制加入人工校验逻辑。
RAG 准确率与响应速度的优化
针对运维场景中“文档多、日志杂、实时性强”的特点,我们做了以下优化:
-
查询策略优化:
- Multi Query - 多查询策略: 一个问题,多种问法
- RAG-Fusion - 多查询结果融合策略: RAG-Fusion是Multi Query的进化版,不仅生成多个查询,还使用了**倒数排序融合(Reciprocal Rank Fusion, RRF)**算法来合并结果,RRF只关心排名,不关心绝对分数
- Decomposition - 问题分解策略:把一个复杂问题拆解成多个简单的子问题,逐个击破
- Step Back问答回退策略: 不直接回答具体问题,而是先生成一个更抽象、更通用的"回退问题",从更高层次理解用户意图,然后再回答原问题
- HyDE(假设性文档嵌入):1. 让LLM先"编"一个假的答案(可能包含错误,但没关系)2. 把这个假答案转成向量 3. 用假答案的向量去搜索真实文档
-
准确率优化(Precision):
- 混合搜索(Hybrid Search): 结合 向量搜索(语义) 和 关键词搜索(BM25/精确匹配)。运维中很多专有名词(如特定的 Error Code)用向量搜索容易偏移,混合搜索能大幅提升召回率。
- 重排序(Reranking): 在粗排召回 Top 20 后,使用特定的 Rerank 模型进行精排,确保最相关的排故文档排在第一位。
- 父子文档切分(Parent-Document Retrieval): 检索时匹配小的 Chunk,但给模型提供其所在的整个段落上下文,解决信息碎片化问题。
- CRAG:纠错检索增强生成:CRAG的全称是Corrective Retrieval-Augmented Generation(纠错检索增强生成)。简单来说,CRAG就是给RAG系统加了一个"质检员",在把检索结果交给LLM之前,先检查一下这些内容靠不靠谱
-
响应速度优化(Speed):
- 多级缓存: 针对高频故障问题,我们在 Embedding 层加入了 Redis 缓存,命中则直接返回。
- 流式输出(SSE): 正如项目中提到的,我们利用 SSE 技术,让模型边检索边生成,减少用户的首屏等待时间。
RRF(Reciprocal Rank Fusion,倒数排名融合)
RRF 的逻辑非常简单且暴力:它不看各个搜索引擎给出的具体分数,只看排名。
- : 某个被检索出来的文档。
- : 所有的检索系统集合(如 )。
- : 文档 在该系统中的排名(从 1 开始)。
- : 一个常数(通常设为 60),用来平滑排名带来的权重差异。
上下文压缩
10轮/70%
当对话轮数增多,我们会把之前的对话内容进行处理,比如对前30轮历史对话进行总结摘要,作为长期记忆。
这个问题在实际使用中确实会遇到,我设计了一个分层记忆管理机制:
- 第一层是滑动窗口记忆,保留最近5轮对话的完整内容,这部分会直接放入prompt中,保证对话的连贯性。
- 第二层是摘要记忆,当对话轮数超过5轮时,会把第5轮之前的对话进行摘要压缩。摘要会保留关键信息,比如用户提到的核心问题、重要参数、已经解决的问题等,把10轮对话压缩成2-3句话。
- 第三层是向量记忆,所有历史对话都会向量化存储在向量数据库中。当用户提到”之前说的那个问题”时,可以通过向量检索找回历史对话内容。
这三层记忆相互配合,既保证了短期对话的连贯性,又支持长期对话的信息检索,还避免了上下文窗口溢出的问题。在实现上,我会在每次调用大模型前检查token数量,如果超过阈值(比如上下文窗口的80%),就触发摘要压缩逻辑。这样可以确保系统稳定运行
多Agent协同
多agent协同主要有三种设计模式:层级模式,平等协同,流水线
Multi-Agent在我的项目中主要体现在Plan-Execute-Replan模式中,通过Planner、Executor、Replanner三个子
Agent协作完成复杂任务。
协作机制主要是通过共享上下文来实现的:
。首先有一个全局的Context,里面包含了任务目标、执行计划、当前步骤、历史结果等信息
。Planner读取任务目标,生成结构化的执行计划,更新到Context中
。Executor读取Context中的当前步骤,调用对应工具,将结果写回Context
。Replanner读取执行结果,评估是否需要调整计划,更新Context中的计划和步骤
。这样循环往复,直到任务完成
这种设计的好处是每个Agent职责单一,Planner只负责规划不执行,Executor只负责执行不规划,Replanner只
负责评估不具体干活。另外,这三个Agent底层可以使用不同的大模型,比如Planner用推理能力强的模型,Executor用速度快的模型,这样可以在性能和成本之间做权衡。
SSE技术
- SSE和WebSocket都是实现实时通信的技术,但原理和适用场景不同。SSE,也就是服务器发送事件,它是基于HTTP协议的。它的工作方式是,客户端发起一个普通的HTTP请求,但服务器不立即关闭连接,而是保持这个连接打开,并按照特定的格式(text/event-stream)持续地、一段一段地向客户端推送数据。
- 而WebSocket是一个独立的协议,它在初次连接时通过HTTP协议进行握手,握手成功后,连接就升级为
WebSocket协议,之后双方就可以在这个连接上进行全双工的双向通信了,服务器可以随时发消息给客户端,客户端也可以随时发消息给服务器。
在选择时,我会考虑:如果需要双向实时交互,比如在线聊天、协同编辑,肯定选WebSocket。
如果只需要服务器向客户端推送实时数据,比如股票行情、通知、或者像我项目里的AI对话流,SSE就足够且更
简单,因为它基于HTTP,不需要处理新的协议,后端实现和调试也方便一些。
选择SSE主要是出于简单和够用的考虑,我们的场景主要是服务器向浏览器单向推送AI生成的文本,不需要双向
通信,SSE的协议比WebSocket更轻量,实现起来也简单,对于流式文本这种场景非常适。用户体验就像是在看
一个人实时打字。
SSE基于HTTP协议,不需要特殊的协议支持,使用标准的HTTP连接。在建立连接后,将HTTP头部的Content-
Type改成text/event-stream就可以了,后续发送消息要按照SSE数据格式发送。
SSE的数据格式非常简单,每条消息由多个字段组成,每个字段由字段名、冒号和字段值组成,以换行符分隔。
agent的评价指标
任务成功率 (Success Rate / Pass@1):
Agent 独立完成预设运维任务(如“查出昨晚 2 点 CPU 飙升的原因”)的百分比。
效率:
平均用了多少步,重规划次数 (Re-plan Count): 在 Plan-Execute-Replan 模式下,Agent 纠正错误的平均轮数。
工具调用准确率 (Tool Call Accuracy)
Token 消耗与成本 (Cost per Task)
prompt设计
1 | |
一、流式输出
- 前端实现大模型流式输出,SSE与WebSocket选型逻辑是什么?各自优缺点、适用场景(结合高并发、跨端兼容)?
-
选 SSE:如果只需要 Server → Client 的单向流(大模型逐字吐词),且客户端只需偶尔发送指令,基于HTTP 请求。原生支持自动重连,支持断点续传
-
选 WebSocket:如果需要 Client ↔ Server 频繁、低延迟的双向实时交互。基于WS协议,需要握手升级,需手动实现重连逻辑
- 流式返回过程中网络中断、前端重连,后端如何恢复上下文继续输出?如何避免重复输出、丢包?
- 前端:前端在接收流式数据时,必须维护两个状态:
message_id(当前对话的唯一标识)和cursor(已成功接收并渲染的字符长度,或 Token 序列号),如果你使用的是标准 SSE,可以通过下发数据的id字段来实现。断网重连时,浏览器会自动在 Header 中带上Last-Event-ID,这就天然解决了游标传递的问题 - 后端:后端在接收到 LLM 的流式吐字时,不仅把数据 Flush 给前端,同时将完整的字符串(或 Token 列表)追加写入 Redis 缓存(Key 为
message_id)。断网处理:连接断开,后端停止向前端 Flush,但继续接收 LLM 的返回并写完 Redis,直到生成结束。重连恢复:前端带着message_id和cursor(比如 50,表示已收到 50 个字符)发起重连。
- 用户点击“停止生成”,后端如何立即终止LLM推理、释放GPU/CPU资源?如何避免资源泄露?
- 前端:主动切断网络连接,在底层强制关闭底层的 TCP 连接,向后端发送网络中断信号
- 后端:一旦捕获到客户端断开异常,必须立刻调用 HTTP 客户端,强行中断与下游 LLM API 的长连接
- 流式返回时,如何插入非文本事件(工具调用标记、思考过程、错误提示、分段标识),且不影响前端渲染?
- 绝对不能在流中直接推纯文本,必须采用“结构化 JSON + 类型的多路复用(Multiplexing)”设计
- 每一次 Chunk 都必须是一个带有
type(类型判别器)的 JSON 对象,如"type": “text”;“type”: "thinking"等
- 多轮对话+流式输出,如何保证消息不乱序、上下文不丢失?
每个数据帧必须携带 Sequence ID(自增序号)。前端拿到 Chunk 后放入一个优先队列(Priority Queue),只有按严格递增序号才渲染上屏,遇到跳号则等待缓冲,后端通过 Session ID 将历史消息存入 Redis 或数据库(形成对话树)。每次请求前,捞取历史拼接组装为 messages 数组传给 LLM
- 跨服务流式透传(Java/Go后端+Python模型服务)如何实现?
- Java,使用响应式客户端
WebClient去请求 Python 端,将响应映射为Flux<String>,然后直接通过SseEmitter或返回Flux<ServerSentEvent>将流推给前端。这样 Python 吐一个词,Java 瞬间就透传一个词
- 高并发下(QPS≥1000),大量SSE长连接如何做连接复用、心跳检测、超时释放?
- 强制开启HTTP/2,利用多路复用,大幅复用底层 TCP 连接, 后端采用异步非阻塞模型(NIO)
- 后端开启定时任务,每隔一段时间(如 15 秒)向客户端推送
: keep-alive\n\n(冒号开头的特殊帧) - 在业务层设置最大存活时间(如单次大模型对话最多允许连 5 分钟),超时后强行调用
close()切断流
- 避免OOM的核心优化点?
-
不要在内存中使用大字符串变量拼接完整的 LLM 回复。必须边读边发,发完即弃,让内存中始终只有当前正在处理的一个 Chunk
-
彻底的级联清理, 客户端断网后,SSE 实例变成了“僵尸”, 第一时间强行切断下游大模型 API 的请求,并从全局活跃连接 Map 中彻底移除该实例
- 流式输出场景中,如何实现内容安全实时截断(检测到敏感词立即停流、清理上下文)?
- 滑动窗口:在内存中维护一个滑动窗口,每次接收到 LLM 的新 Token,先追加到窗口中,使用 DFA 算法 在窗口内进行极速匹配
- 流式返回时,如何精准统计Token消耗(逐段统计、总消耗汇总),适配计费场景?
- 模型原生特性:目前主流大模型(如 OpenAI、DeepSeek)的 API 已全面支持在流式返回的最后一个 Chunk 中附加精确的 Token 消耗
- 如果生成到一半客户端断网:在后端(Java/Go)引入与大模型严格一致的 Tokenizer 库
- 小程序、APP、PC端对流式输出的兼容性差异如何处理?如何解决部分端流式渲染卡顿问题?
-
在前端维护一个接收队列(Buffer),类似于上面的滑动窗口
- 接收层:网络回调疯狂往 Buffer 里推字符串,不触发 UI 更新。
- 渲染层:开启一个定时器(如
setInterval设置 50ms)或借助requestAnimationFrame,按固定帧率从 Buffer 中掏出数据,一次性更新到 UI 的 State 中
- 流式推理时,LLM模型报错(如中途断连),如何设计兜底策略,保证用户体验?
- 降级:增加行内错误提示,在流式中断的文本末尾,直接追加一个结构化的错误尾巴,并提供操作项
- 多模型降级:静默切断并换备胎模型重发
- 如何实现流式输出的“断点续打”?用户刷新页面后,如何恢复之前未完成的流式内容?
- 游标+缓存队列
- 跨服务流式透传时,如何做日志埋点(每段输出、耗时、异常),支撑全链路追踪?
二、Agent核心原理
- Agent执行环路(Plan→Act→Observe→Reflect)在生产中如何落地?
看门狗(Watchdog)阻断,严控单个任务的最大流转节点数(比如 15 步),到达阈值强制终止
- 各环节的异常处理(如Act失败、Observe无结果)如何设计?
- ACT失败:
- 参数给错:进行前置参数校验,利用拦截器进行schema校验
- 底层工具失败:捕获异常,并包装成“人类语言”返回给观察(Observe)环节
- Observe无结果:
- 空结果:利用占位符,返回明确的系统提示语
- 超限:做硬性截断,并在尾部追加提示
- ReAct框架在实际开发中,如何避免“思考与行动脱节”?
- 直接使用现代大模型原生的 Function Calling(或 MCP 协议), 将底层工具定义为严格的 JSON Schema 传给模型,从模型底层强制对齐了“想做什么”和“实际调用什么”
- 记忆锚定:在每一轮的系统 Prompt 尾部,动态注入一个“目标锚点”,加上一句强制提示词
- 如何优化Reason步骤的准确性?
-
引入“检查者”模式,将 Reason 拆分为两个独立的子 Agent
- Actor(规划者):负责根据当前上下文输出下一步的思考和行动计划
- Critic(审查者):拿到 Actor 的计划后,对照系统约束条件(比如权限规则、历史错误记录)进行 Review。只有 Critic 给出
APPROVED状态,计划才会流转到 Act 阶段;如果REJECTED,则打回重做
-
多分支搜索
- Tree of Thoughts (ToT) 在 Reason 阶段,让模型针对当前困境生成 3 条不同的思考路径,然后调用一个轻量级的评估函数(或自我打分)对这 3 条路径进行评估,选择得分最高的一条继续往下走
-
使用原生推理模型
- Agent工具调用的Schema设计核心是什么?
-
Schema 中,
description字段决不能偷懒,不仅要描述“是什么”,还要描述“什么时候用”和“格式长什么样” -
扁平化优于深层嵌套,将复杂的结构拆解为几个并列的简单扁平参数
-
强约束与枚举(Enum)物理锁死幻觉,若参数有固定的取值范围例如,订单状态必须明确列出
enum: ["PAID", "SHIPPED", "CANCELLED"]
- 如何保证LLM正确选择工具、传递正确参数(避免参数缺失、类型错误)?
- 工具检索加路由,做召回(Top-K),只把最相关的 3-5 个工具 Schema 塞给大模型
- Few-Shot(少样本)注入
- 善用 Enum 和 Default,能用枚举就绝不用字符串,锁死可选值
- 多步工具依赖(如“查用户→查订单→查物流”),如何设计依赖管理、避免重复调用、死循环?
- 引入有向无环图(DAG)或状态机。在定义 Schema 时,明确输入输出依赖
- 工具调用缓存,
ToolName + 参数哈希值 + SessionID作为 Key 建立短生命周期的缓存,当检测到大模型在同一个会话中发起完全相同的函数调用时,网关直接拦截,0 延迟返回 Redis 中缓存的上一次查询结果 - 看门狗熔断机制
- Agent的反思机制(Reflection)如何实现?
- 单体自反思:当 Agent 执行某个 Action 报错时,宿主代码拦截该异常,后端不直接退出,而是将异常信息包装成一段反思提示词,追加到历史对话中
- 加入审查者,引入一个专门的 Critic Agent
- 如何让Agent从执行失败中学习,优化下一轮决策?
- 记忆注入:构建错题本,存入向量数据库,下一个相似的任务进来时,先检索经验池
- 路由控制进行统计打分:后台统计每个 MCP 工具的健康度和成功率,若经常失败,系统自动降低该工具的“置信度分数”
- 自动prompt演进(教师-学生模型):调用一个更高阶、算力更强的模型(如 GPT-4o 或 DeepSeek-R1),让它审视这些失败记录,并修改prompt
- Agent的短期记忆、长期记忆如何设计存储结构?
- 工作记忆:hashmap
- 短期记忆:redis
- 长期记忆:向量数据库
- 如何平衡记忆容量与查询速度?
-
先粗筛再后筛:为每条记忆强绑定标量标签(或者加一层路由),先把几百万的数据量物理隔离到几千条以内,彻底屏蔽容量带来的检索延迟
-
使用近似最近邻(ANN)算法,HNSW(分层可导航小世界图),在内存中构建多层跳表图,将查询时间复杂度从 降到
-
IVF-PQ,浮点数压缩成短整数,牺牲约 1%~3% 的召回精度,能省出几十倍的内存开销
HNSW:
-
小世界
- 普通连接: 每个点和离自己最近的几个邻居连线
- 小世界连接: 除了近邻,我们随机建立一些**“远距离跨度”**的连线
-
分层
- 最顶层:节点极少。你在这里跨一步,可能就横跨了半个中国
- 中间层(省道/城市层): 节点稍多。你在这里缩小搜索范围
- 最底层(街道层): 包含了所有的数据点。你在这里进行最后的精准定位
IVF-PQ:
- IVF: 就是分堆,利用 K-Means 聚类将所有向量分成 个簇
- PQ:编号代替原向量,实现压缩,高维向量切割成多个低维子向量,每个子向量独立进行聚类,最后用对应的“聚类中心编号”来表示原向量
- 高并发场景下,Agent任务排队、限流、优先级调度如何实现?(结合实际业务场景,如付费用户优先)
使用 Redis + Lua 脚本实现分布式令牌桶算法,限流不是“一刀切”。采用动态令牌桶,付费用户的令牌产生速度更高,且拥有更大的“突发流量(Burst)”容忍度
- Agent调用工具超时,如何设计重试策略、熔断机制、降级方案?兜底回复如何设计才不生硬?
重试:执行重试前,拦截器必须判断工具的幂等性。如果是查询类工具(如查天气),放心重试;如果是执行类操作(如发邮件、写数据库),绝不自动重试,必须抛出异常转交人类确认
熔断:在后端统计工具调用的失败率(例如过去 10 次调用失败 5 次以上),直接将该工具状态置为 OPEN
降级:主工具超时,自动路由到备用工具
- Agent生成的SQL/代码需要执行,如何设计沙箱环境、权限隔离,避免越权操作、注入攻击?
为 Agent 分配一个独立的、只读的(Read-Only) 影子数据库或只读从库账号
沙箱实例的生命周期与单次代码执行严格绑定。执行完毕后,无论成功失败,立即销毁实例。绝不复用沙箱,防止恶意代码埋设内存后门
-
LangChain、LangGraph在生产中如何选型?
-
LangGraph的状态机设计,如何适配复杂业务流程(如审批、工单)?
-
Agent执行过程如何做可观测?每一步的思考、工具调用、耗时、Token消耗、异常,如何全链路追踪?
将大模型的推理过程映射为分布式的 Trace 树
重新映射 Trace 与 Span 模型
不要试图把所有的日志拍扁在控制台,必须构建具有层级关系的 Span 树:
- Root Span (Trace ID):代表用户的单次完整 Task(如“帮我查订单并退款”)。
- Agent Loop Span:代表单次 PAOR 循环(第 1 轮思考、第 2 轮反思…)。
- Execution Spans (叶子节点):
- LLM Span:记录对大模型的网络请求。
- Tool Span:记录具体工具(如
search_db)的本地或 RPC 执行。
- 多个用户同时触发同一个Agent任务,如何做幂等设计,避免重复执行(如重复查询数据库、调用接口)?
请求合并:当用户 A 的 Agent 正在辛苦调用 API 查数据时,用户 B 和 C 也发起了相同的请求,B 和 C 的请求到达网关后,发现 正在执行中,它们不会去唤醒新的大模型,而是直接挂起等待。当 A 的 Agent 彻底执行完后,将结果一并返回给 A、B、C
**分布式锁:**在 Agent 进入复杂的 Act(执行)节点前,向 Redis 申请一把带有过期时间的锁
**缓存:**将执行完毕的结果直接存入 Redis。后续相同的参数请求 0 延迟返回
- Agent如何安全传递用户身份(登录态、权限),调用工具时避免身份泄露、越权?
在提供给大模型的 Tool Schema 里,坚决不要定义 user_id、token 等鉴权参数,当 Agent 框架准备发起真实的底层微服务 API 调用时,底层的 RPC/HTTP Client 拦截器会自动从上下文中取出 Token 并塞入 Header
- 如何实现Agent执行过程的可回放、可打断、可人工干预?(落地场景:客服Agent出错时人工接管) Agent的任务分解能力如何优化?
可回放:将 Agent 的每一步(规划、工具调用参数、API 原始返回、反思)都作为独立的 Event 存入数据库
可打断:将当前会话的运行状态存在 Redis 中,一旦查到状态被客服改为 PAUSED 或 STOPPED,当前线程立刻抛出 InterruptException 挂起或销毁,停止消耗 Token
- 如何让Agent正确拆分复杂任务(如“写方案→查资料→改初稿”)?
多智能体(Multi-Agent)架构,去兜底大模型规划能力的不可控,RePlan
- 开源Agent框架(LangChain、AutoGen、MetaGPT)在生产中落地的坑有哪些?如何规避?
LangChain 为了做到极度通用,封装了极其复杂的类继承关系。它在底层偷偷塞入了很多自带的 System Prompt(比如针对特定 Agent 类型的格式化指令)
只把 LangChain 当作一个工具库(用它的 Document Loader 加载文件、用它的 Text Splitter 切割文本),而在最核心的“大模型调用、Prompt 拼接、工具路由”环节,直接使用官方原生 SDK(如 OpenAI SDK 或 Spring AI 原生接口)手写逻辑,做到 100% 的白盒可控
- Agent与现有后端系统(Java/Go)对接,如何保证接口调用的稳定性、一致性?
绝对零信任 Agent 的输出,必须在架构中间建立隔离带
- 如何评估Agent的任务完成率?生产中如何统计Agent的成功率、错误率、步骤合理性?
任务成功率:
效率:
三、RAG生产落地痛点题
- 百万级文档RAG,检索延迟要求<200ms,如何设计索引、分片、缓存架构?(结合Milvus/Chroma实际部署) 文档频繁更新/删除,向量库如何保证实时一致性?
索引:HNSW
文档更新/删除: 使用元数据对文档进行索引
- 如何避免召回旧知识、脏数据?
使用元数据时,加上 status 和 version 字段,当知识库管理员将某篇文档下线或更新时,后台异步批量将对应 Chunk 的 status 置为 ARCHIVED 或 DELETED
- 同一用户同一问题多次查询,如何做检索结果缓存?
一级缓存:精确匹配拦截
二级缓存:语义缓存(Milvus查询相似度)
-
如何处理“缓存过期”与“新知识更新”的矛盾?
-
用户问题模糊(如“查一下最近的订单”),如何做意图识别+查询改写+多路召回,提升召回率?
详见前面召回率提升
- 表格、带格式PDF、图片文本的RAG,如何处理才能不丢失结构信息(如表格行列关系、PDF排版)?
摘要索引:对提取出的 HTML 表格生成一段高度概括的总结,存入向量数据库,作为搜索匹配的靶点,当用户查询时,检索器命中摘要,系统则提取出背后的完整 HTML 表格,将其喂给大模型作为上下文
-
长文档(10w字+)RAG出现“中间内容丢失”,如何用父子分块、分层检索、重排序解决?
-
混合检索(稀疏+稠密)在生产中如何调参?如何平衡召回率与检索速度?
BM25 稀疏 + 余弦相似度 稠密 + RRF 倒数排名索引
- RAG与多轮对话结合,如何实现“基于历史上下文的自动检索”?避免重复检索、无效检索? 如何避免RAG检索到大量无关片段,导致LLM回答跑偏?(落地优化手段)
在网关层部署一个极小参数的意图识别模型(或基于 FastText 的分类器),将输入分为两类:Needs_Context 和 Chitchat_Or_Followup:如果用户是在针对上一轮回答进行纯逻辑追问,或者进行闲聊,直接跳过 RAG 检索阶段,仅携带短期记忆(Redis 中的对话历史)让大模型作答
-
生产环境如何自动化评估RAG效果?(召回率、MRR、Answer Relevancy的实操方案)
-
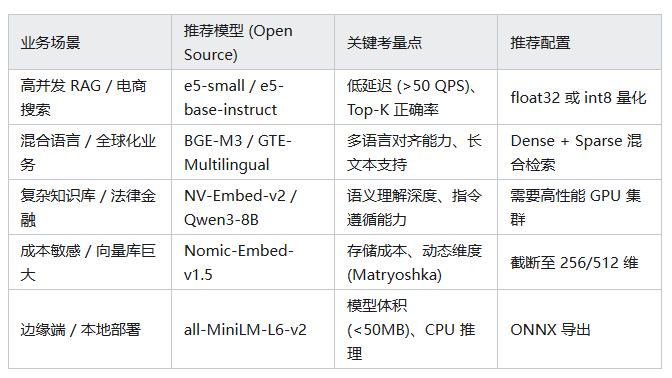
Embedding模型如何选型?中英文文档混合场景,如何选择合适的Embedding模型,平衡效果与速度?
- 向量检索中,余弦相似度、点积、欧氏距离的实际应用差异?如何选择?
余弦:只关注两个向量在多维空间中的“夹角”,完全忽略向量的绝对长度
点积:既看方向,又看长度。方向越一致、向量本身的绝对值越大,得分越高
欧氏距离:测量两个点在空间中的直线绝对距离。既对方向敏感,也对长度极其敏感
51.RAG的rerank重排环节,如何选择重排模型?如何优化重排速度?
cross-encoder 模型 ,
优化重排速度:Top-K限制
- 动态知识更新场景(如每日新增文档),RAG如何设计增量更新机制,避免全量重新向量化?
元数据索引
- 如何处理RAG中的噪声文档(如无效文档、重复文档)?如何做文档去重、过滤?
对整个文档或单个 Chunk 的纯文本计算哈希值。在入库前通过 Redis 或布隆过滤器(Bloom Filter)进行 复杂度的校验。如果哈希已存在,直接拦截,拒绝向量化
-
RAG服务高并发下,如何做负载均衡、水平扩展?
-
RAG与Fine-tuning在生产中如何选型?什么场景下优先用RAG,什么场景下需要微调?
RAG 是给大模型一本可以随时翻阅的“最新参考书”(开卷考试);而 Fine-tuning 是让大模型通过大量练习把某种技能或知识“内化进骨子里”(闭卷考试)
| 维度 | RAG (检索增强) | Fine-tuning (微调) |
|---|---|---|
| 知识时效性 | 极强 秒级更新,只需更新向量库 | 差。每次更新数据都需要重新训练,成本高、周期长 |
| 外部知识深度 | 高。能处理数百万文档,且能精准溯源 | 低。模型参数容量有限,容易产生“知识幻觉” |
| 输出格式/风格控制 | 中。依赖 Prompt 约束,长文本下容易失效 | 极强。能完美控制 JSON、SQL 或特定医学术语的输出格式 |
| 端到端延迟 | 高。涉及检索、重排,增加 100-500ms 延迟 | 低。推理路径短,无需额外检索步骤 |
| 成本投入 | 持续性成本。向量库存储、Embedding/Rerank 算力 | 一次性高投入。训练算力、高质量标注数据的人工成本 |
RAG: 动态知识库, 降低幻觉风险
Fine-tuning: 极致的性能/成本优化, 延迟极其敏感
- 如何解决RAG的“检索滞后”问题?(如文档更新后,检索结果不能及时更新)
元数据状态更新,实时
四、LLM工程化与高并发、稳定性
峰值QPS 100+的LLM接口,如何做排队、削峰、批量推理、优先级调度?(结合vLLM/TGI实操)
LLM推理加速方案(vLLM、TGI、TensorRT-LLM)的原理与落地差异?如何选择?
模型量化(INT8/INT4/FP8)的原理?生产中如何平衡量化精度与推理速度?量化后的坑如何规避?
模型API突然报错、限流、宕机,后端如何设计熔断机制、切换备用模型?如何保证用户无感知?
如何防止恶意用户构造超长上下文、高频请求,刷Token造成成本暴增?(落地限流、拦截方案)
生产中如何实现多模型调度?(小模型处理简单任务、大模型处理复杂推理)如何设计调度策略?
LLM推理服务GPU资源有限,如何做资源隔离、队列优先级、超时抢占?
异步Agent任务(执行时间>10s)如何设计?(任务状态管理、重试机制、结果通知、落库方案)
如何实现LLM请求全链路压测?如何模拟真实对话流量、流式请求场景?
微服务架构下,AI模块与Java/Go后端如何实现分布式事务、最终一致性?
Agent服务如何高可用部署?多实例、负载均衡、灾备设计的核心要点?
如何做LLM结果、Embedding、检索结果的缓存设计?如何设置缓存过期时间?
日志量巨大(每轮对话10KB+),如何设计存储、检索、审计、降冷方案?(结合ELK实操)
如何做权限控制?(数据权限、工具权限、功能权限)如何避免Agent越权操作?
Docker + K8s部署Agent/LLM服务,需要注意哪些点?(资源配置、健康检查、滚动更新)
MLOps如何应用在Agent系统?(模型版本管理、实验跟踪、CI/CD流水线落地)
五、安全、成本与架构设计
Prompt Injection攻击的原理与生产级防御方案?(结合实际落地的防御性Prompt、拦截机制)
如何防止敏感信息(用户手机号、订单号)进入LLM,造成数据泄露?(脱敏方案实操)
生产中如何控制Token消耗与模型成本?(限流、缓存、模型选型、批量推理等组合方案)
私有部署vs API调用如何选型?各自的成本、稳定性、安全性对比?落地场景是什么?
如何保证Agent行为可解释、可审计、可回溯?(日志设计、链路追踪、行为记录)
设计一个企业内部知识库问答Agent,架构图+核心流程+性能优化点?(落地级设计)
设计一个Text2SQL Agent,如何解决SQL注入、表结构识别、复杂查询(多表关联)问题?
设计一个客服多Agent系统,如何实现意图识别、知识库检索、工单生成、人工转接的无缝衔接?
设计一个低延迟、高并发的RAG服务,核心架构与性能优化点?(结合百万级文档场景)
如何设计多Agent协作系统?(分工、通信、调度、冲突解决)结合内容创作场景实操?
从后端工程师角度,如何搭建可上线的Agent平台?(核心模块、技术选型、工程化保障)
如何做输出内容审核、毒性检测?如何避免Agent生成违规、不当内容?
灾备设计:主模型/主服务挂了,如何自动切换到备用,不影响用户体验?(落地流程)
设计一个自动化运维Agent,如何实现日志读取、问题定位、命令执行、异常提醒?
多模型服务网格如何设计?如何实现模型的动态切换、负载均衡、健康检查?
如何处理Agent执行过程中的“长尾任务”(执行时间长、资源消耗大)?
如何优化性能、控制成本?
你做这个项目遇到过什么困难/挑战?
其实最大的困难是在于写文档,之前的告警处理手册其实是很多人都会往里面加东西,很多步骤可能表述的不是很清晰,最蛋疼的是有些超链接,链接到其他文档,写的不完整
- 那对于我们做RAG来说,第一步就是要把文档写完整完善,否则会影响召回的质量,以及大模型的判断
- 另外我觉得印象比较深刻的点在于,这个项目是我实习到时候偷摸做的,因为实习的时候安排我也值班。
- 值班我就发现了这些痛点,太浪费时间了值班。老是要翻日志看监控,回复很多相同的问题。说白了就是比较打杂,维护老项目。让我打杂但是我不能真打杂浪费时间啊,所以我偷偷做这个项目,好在最后做出来了,不论是对其他人值班,还是对自己值班,真有帮助。我还觉得挺有成就感的
多模态能力
改进方向
- 增加多模态能力
- 支持多租户,多租户隔离,知识库隔离,权限隔离,资源隔离