SegMamba
摘要
摘要。Transformer 架构在建模全局关系方面表现出色。然而,它在处理高维医学图像时带来了巨大的计算挑战。Mamba 作为一种状态空间模型 (SSM),最近成为一种用于对序列数据中的长距离依赖关系进行建模的著名方法,凭借其出色的内存效率和计算速度在自然语言处理领域表现出色。受其成功的启发,我们推出了 SegMamba,一种新颖的 3D 医学图像分割 Mamba 模型,旨在有效捕获每个尺度的全体积特征内的长距离依赖关系。与基于 Transformer 的方法相比,我们的 SegMamba 在整个体积特征建模方面表现出色,即使体积特征的分辨率为 64 × 64 × 64(序列长度约为 260k),也能保持卓越的处理速度。在三个数据集上进行的综合实验证明了我们的 SegMamba 的有效性和效率。此外,为了促进 3D 结直肠癌 (CRC) 分割研究,我们贡献了一个新的大规模数据集(名为 CRC-500)。SegMamba 的代码和有关 CRC-500 数据集的信息可在以下位置找到:https://github.com/gexing/SegMamba
模型
SegMamba 主要由三个组件组成:1)具有多个三向空间 Mamba 块的 3D 特征编码器,用于对不同尺度的全局信息进行建模;2)基于卷积层的 3D 解码器,用于预测分割结果;3)跳跃连接,用于将全局多尺度特征连接到解码器以实现特征重用。图 2 说明了所提出的 SegMamba 的概览。
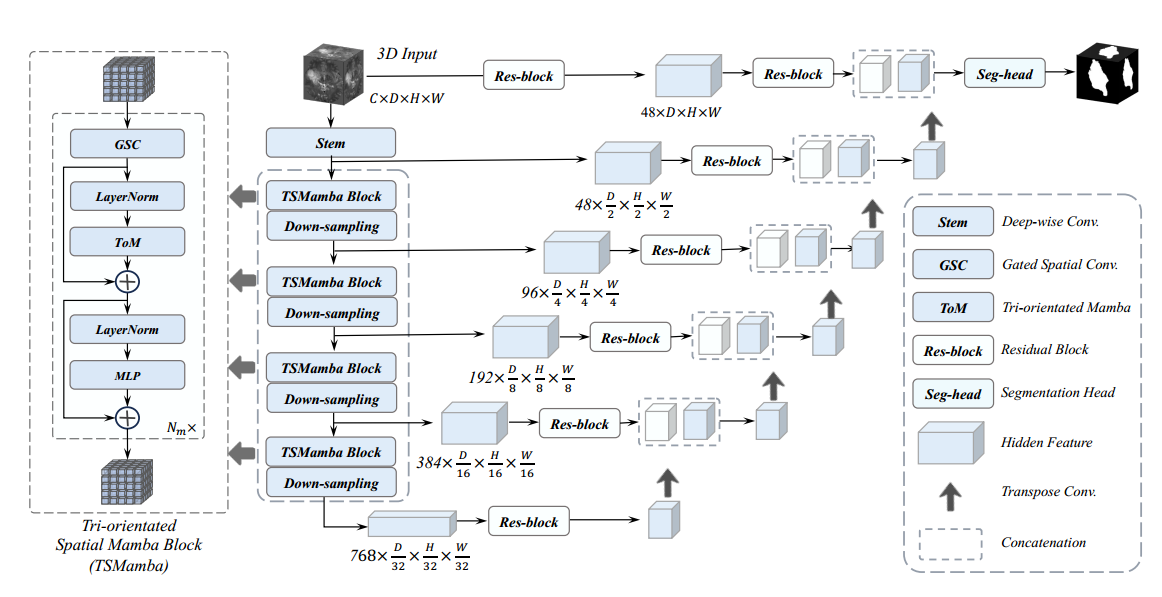
对于 3D 医学图像分割而言,全局特征和多尺度特征建模至关重要。Transformer 架构可以提取全局信息,但在处理过长的特征序列时会产生很大的计算负担。为了减少序列长度,基于 Transformer 架构的方法(例如 UNETR)直接将分辨率为 D × H × W 的 3D 输入下采样为 D 16 × H 16 × W 16。然而,这种方法限制了编码多尺度特征的能力,而多尺度特征对于通过解码器预测分割结果至关重要。为了克服这个限制,我们设计了一个 TSMamba 模块,以实现多尺度和全局特征建模,同时在训练和推理期间保持高效率。
编码器由一个 stem 层和多个 TSMamba 块组成。stem 层提取第一个尺度特征 z0 ∈ R 48× D 2 × H 2 × W 2。 然后,z0 被输入到每个 TSMamba 块和相应的下采样层。
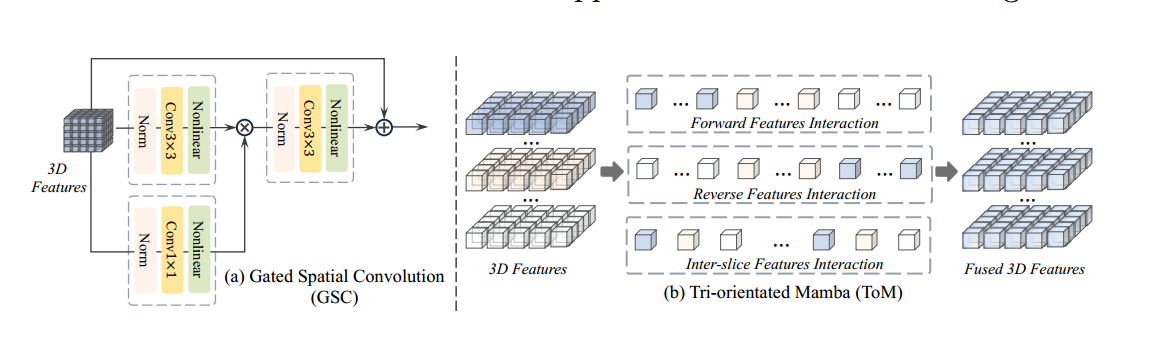
门控空间卷积 (GSC) Mamba 层通过将 3D 特征展平为 1D 序列来对特征依赖性进行建模。因此,为了在 Mamba 层之前提取空间关系,我们设计了一个门控空间卷积 (GSC) 模块。如图 3 (a) 所示,输入的 3D 特征被送入两个卷积块(一个卷积块包含一个范数、一个卷积和一个非线性层),卷积核大小分别为 3×3×3 和 1×1×1。
然后将这两个特征逐像素相乘,以类似于门机制 [13] 的信息传输进行控制。最后,使用卷积块进一步融合特征,同时利用残差连接重用输入特征。
三向 Mamba (ToM) 在 TSMamba 模块中,为了有效地对高维特征的全局信息进行建模,我们设计了一个三向 Mamba 模块,从三个方向计算特征依赖关系。如图 3 (b) 所示,我们将 3D 输入特征展平为三个序列,以执行相应的特征交互并获得融合的 3D 特征。
结论
提出了第一种基于 Mamba 的通用 3D 医学图像分割方法,称为 SegMamba。我们设计了一个三向 Mamba (ToM) 模块来增强 3D 特征的顺序建模。然后,为了有效地对空间特征进行建模,我们进一步设计了一个门控空间卷积 (GSC) 模块,以在每个 ToM 模块之前增强空间维度中的特征表示。
复现实验
经过一周的安装和配置环境,终于把这个代码给跑了起来,在这里再骂一遍python狗屎的各种版本。超!在看复现数据之前,先了解相关的评价指标
Dice系数
Dice系数是一种集合相似度度量函数,通常用于计算两个样本的相似度,取值范围在[0,1]
其中 |X∩Y| 是X和Y之间的交集,|X|和|Y|分表表示X和Y的元素的个数,其中,分子的系数为2,是因为分母存在重复计算X和Y之间的共同元素的原因
MIoU之前已经了解过了,对于二分类的任务来说,二者思想都是交集/并集,但dice并不是在分母上减去交集,而是将交集在分子上算了两次。
对于多分类来说,Dice是将预测结果转为了多通道,而MIoU只在一个通道上计算。
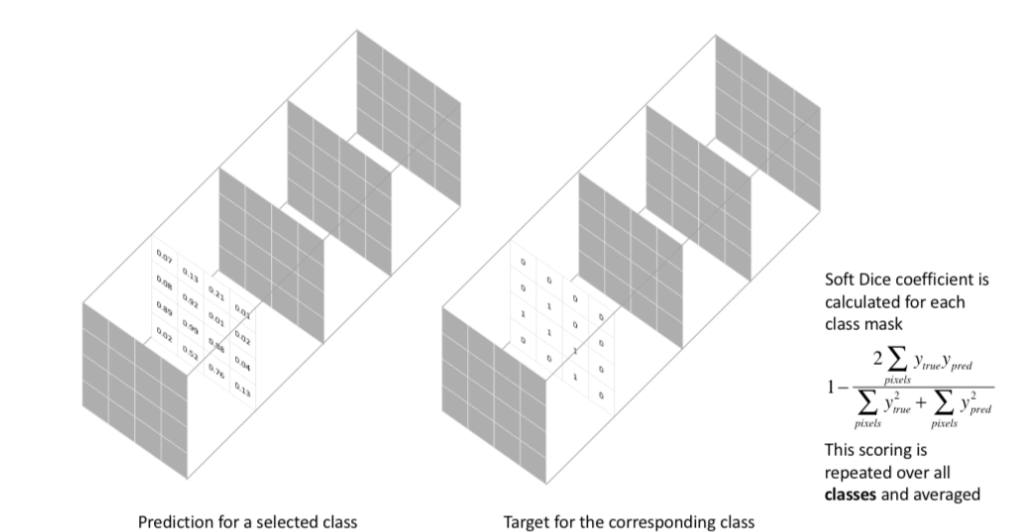
Dice Loss
这种损失函数被称为 **Soft Dice Loss,**因为我们直接使用预测概率而不是使用阈值或将它们转换为二进制mask。Soft Dice Loss 将每个类别分开考虑,然后平均得到最后结果
(1)训练误差曲线非常混乱,很难看出关于收敛的信息。尽管可以检查在验证集上的误差来避开此问题。
(2)Dice Loss比较适用于样本极度不均的情况,一般的情况下,使用 Dice Loss 会对反向传播造成不利的影响,容易使训练变得不稳定。
所以在一般情况下,还是使用交叉熵损失函数。
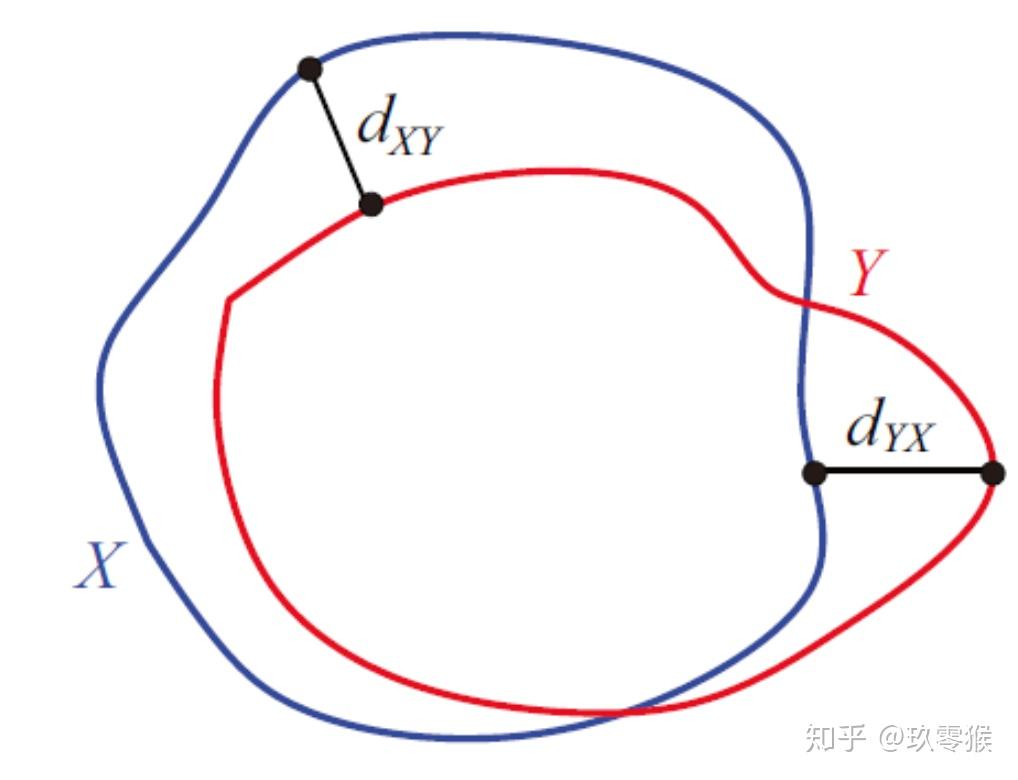
豪斯多夫距离(Hausdorff distance)
一般使用dice衡量区域的重合程度,使用95%的HD( Hausdorff Distance)去衡量边界的重合程度,之所以取95%,是因为要滤去5%的离群点。
Hausdorff distance是描述两组点集之间相似程度的一种量度,它是两个点集之间距离的一种定义形式:假设有两组集合A={a1,…,ap},B={b1,…,bq},则这两个点集合之间的Hausdorff distance定义为:
其中,
‖·‖是点集A和B点集间的距离范式。(如:L2或Euclidean距离).
数据集
BraTS2023 数据集 共包含 1,251 个 3D 脑部 MRI 体积。每个体积包括四种模态(即 T1、T1Gd、T2、T2-FLAIR)和三个分割目标(TC:肿瘤核心、WT:整个肿瘤、ET:增强肿瘤)
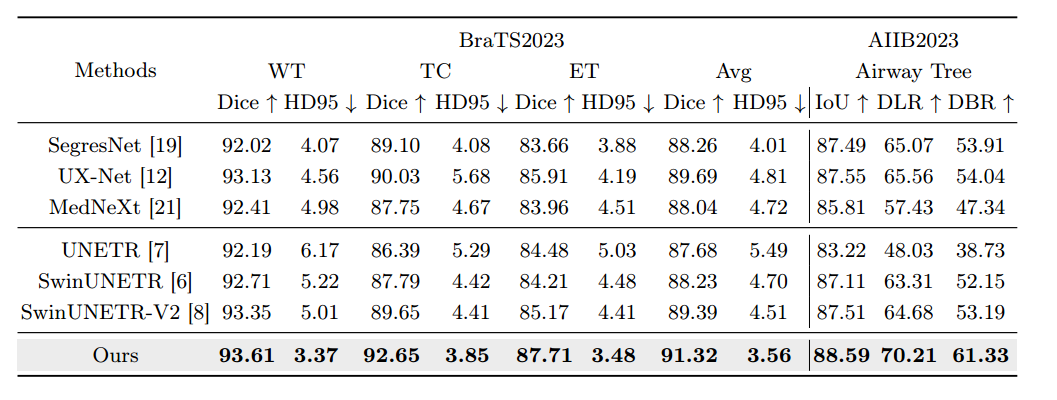
这里复现使用的环境为pytroch 2.01,causal-conv1d 1.0.0 , mamba 1.2.0 (site-page里面mamba-ssm换成了mamba 1.0.1),下表就是复现实验的部分Dice数据:
| Epoch | tc | wt | et | avg |
|---|---|---|---|---|
| 19 | 0.8111 | 0.8987 | 0.7715 | 0.8270 |
| 25 | 0.8550 | 0.9313 | 0.8168 | 0.8676 |
| 35 | 0.8839 | 0.9208 | 0.8588 | 0.8878 |
| … | … | … | … | … |
| 119 | 0.9089 | 0.9292 | 0.8559 | 0.8980 |
使用TensorBoard进行数据可视化
1 | |
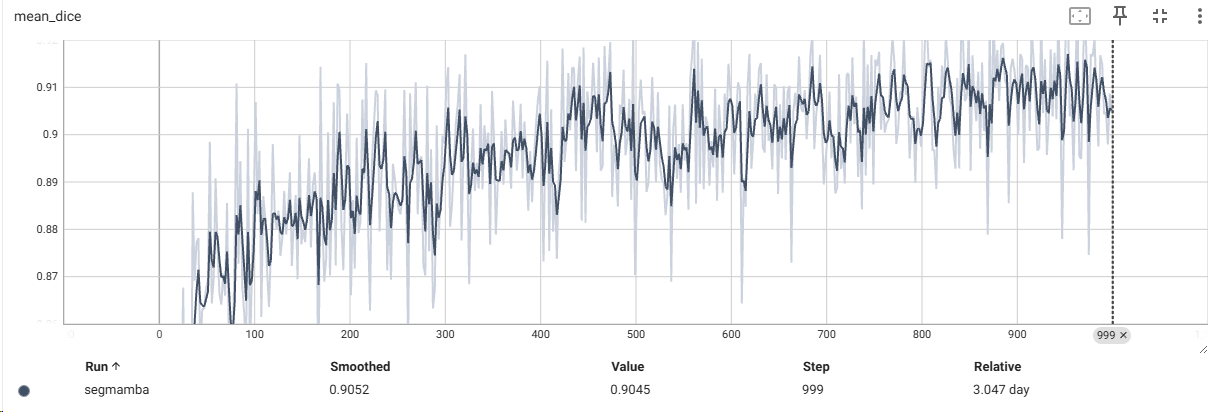
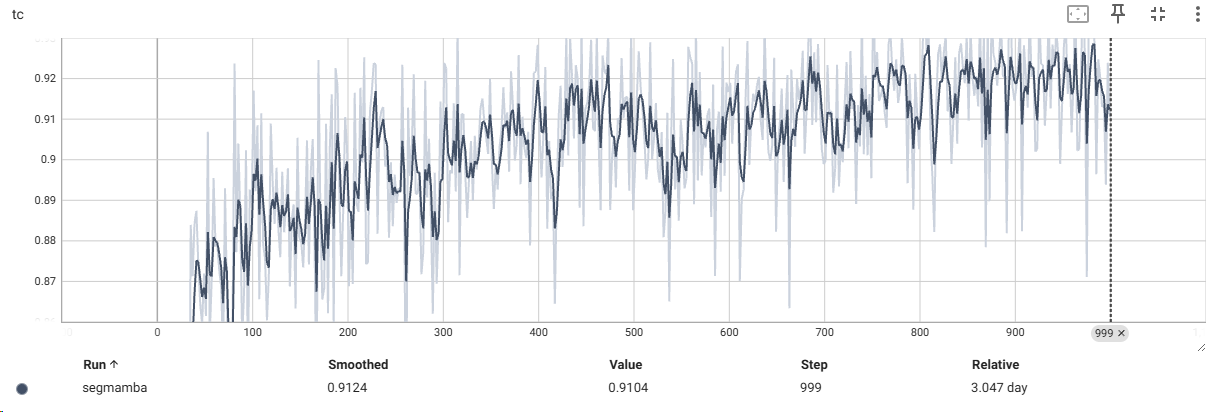
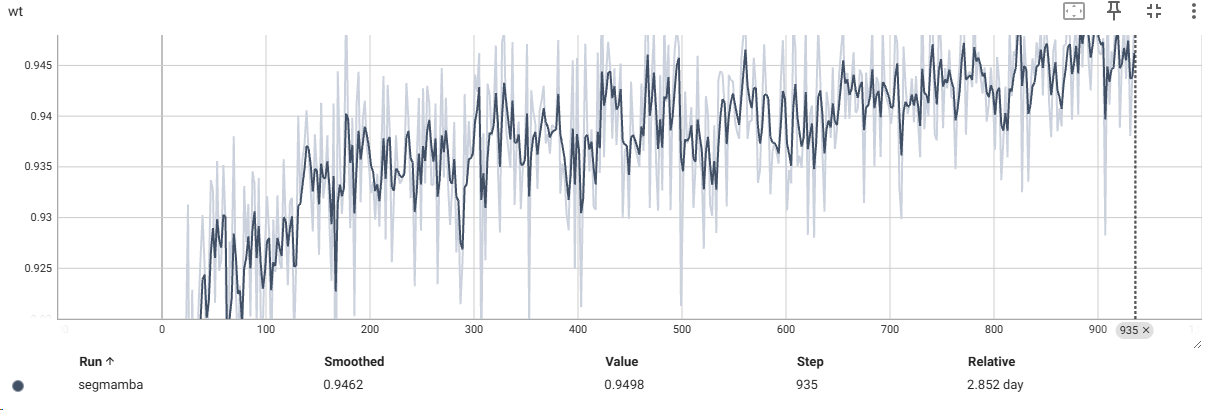
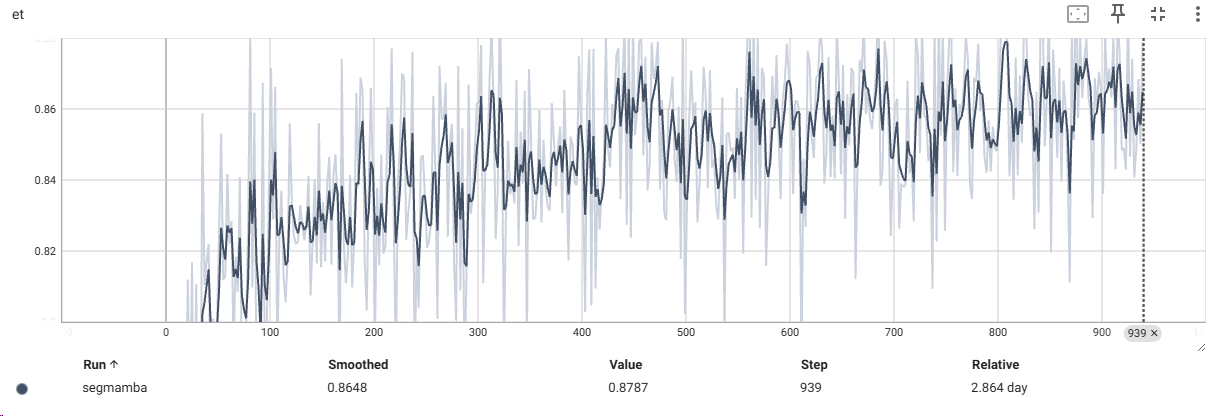
最后附上部分打印的数据
1 | |