现代卷积神经网络模型
前言:依据李沐视频整理
AlexNet
2012年,AlexNet横空出世。它首次证明了学习到的特征可以超越手工设计的特征。它一举打破了计算机视觉研究的现状。 AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。是一个更深更大的LeNet。

主要改进:
-
使用将sigmoid激活函数改为更简单的ReLU激活函数,ReLU激活函数的计算更简单
-
使用了dropout丢弃法防止过拟合
-
使用最大汇聚层MaxPooling替代平均汇聚层
来看看代码实现:
1 | |
VGG
与AlexNet、LeNet一样,VGG网络可以分为两部分:第一部分主要由卷积层和汇聚层组成,第二部分由全连接层组成。其中最大的特点就是VGG使用了VGG块来进行重复。

一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大汇聚层。在最初的VGG论文中 [Simonyan and Zisserman, 2014],作者使用了带有3×3卷积核、填充为1(保持高度和宽度)的卷积层,和带有2×2汇聚窗口、步幅为2(每个块后的分辨率减半)的最大汇聚层。是一个更大更深的AlexNet (重复的VGG块)。
它的思想是使用可重复使用的卷积快来构建深度卷积神经网络,不同的卷积快个数和超参数可以得到不同复杂度的变种。
来看看实现代码:
1 | |
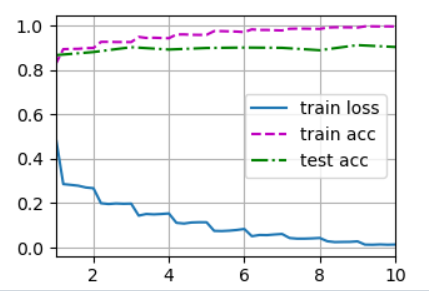
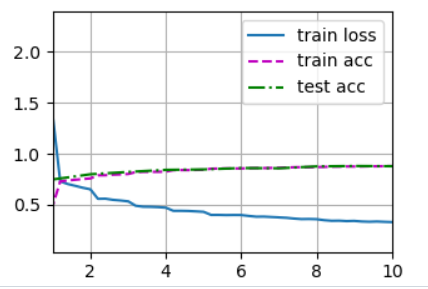
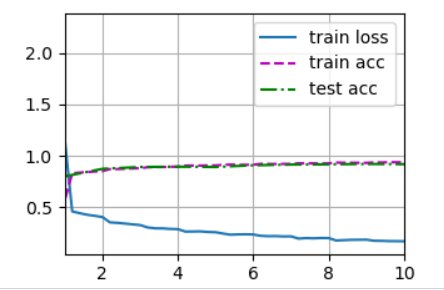
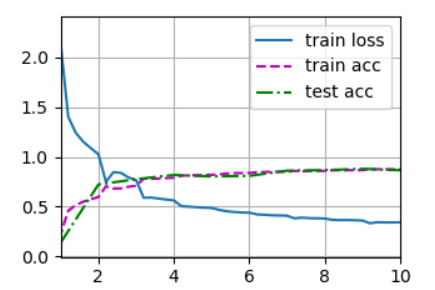
跑出来的结果:
NiN
最初的NiN网络是在AlexNet后不久提出的,显然从中得到了一些启示。 NiN使用窗口形状为11×11、5×5和3×3的卷积层,输出通道数量与AlexNet中的相同。 每个NiN块后有一个最大汇聚层,汇聚窗口形状为3×3,步幅为2。
NiN和AlexNet之间的一个显著区别是NiN完全取消了全连接层。 相反,NiN使用一个NiN块,其输出通道数等于标签类别的数量。最后放一个全局平均汇聚层(global average pooling layer),生成一个对数几率 (logits)。NiN设计的一个优点是,它显著减少了模型所需参数的数量。
结构示意;

特点:
-
无全连接层,使用全局平均池化层来代替VGG和AlexNet中的全连接层,最后使用全局平均池化层得到输出 其输出通道数是类别数
-
交替使用NiN块和步幅为2的组大池化层 逐步减少高宽和增大通道数
-
NiN块使用卷积层加两个1X1卷积层 后者队每个像素增加了非线性性
-
不容易过拟合,更少的参数
又来看看代码:
1 | |
不经常使用
GoogLeNet
首先从名字就能看出是谷歌开发的,其中名字还有玩梗,将L大写,致敬了LeNet。
其中一个独特的结构就是Inception块,这个块的特点就是,小学才做选择题,我全都要 。这个块的名字还和电影盗梦空间原本的英文名一样,取名天才。

Inception块由四条并行路径组成。 前三条路径使用窗口大小为1×1、3×3和5×5的卷积层,从不同空间大小中提取信息。 中间的两条路径在输入上执行1×1卷积,以减少通道数,从而降低模型的复杂性。 第四条路径使用3×3最大汇聚层,然后使用1×1卷积层来改变通道数。 这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。四个路径从不同层面抽取信息,然后再输出通道维合并。这个块跟单3x3,5x5卷积层比,Inception块有跟梢的参数个数和计算复杂度。
GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。 第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使用全连接层。
该网络的结构

继续来看代码
1 | |
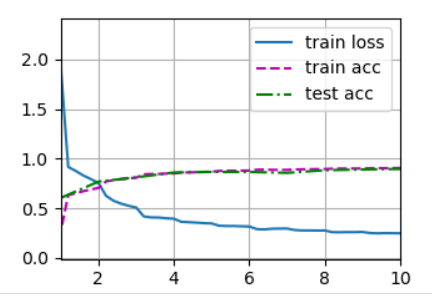
批量归一化
在每次训练迭代中,我们首先规范化输入,即通过减去其均值并除以其标准差,其中两者均基于当前小批量处理。 接下来,我们应用比例系数和比例偏移。 正是由于这个基于批量统计的标准化,才有了批量规范化的名称。固定小批量里面的均值和方差,然后再做额外的调整。
从形式上来说,用x∈B表示一个来自小批量B的输入,批量规范化BN根据以下表达式转换x:
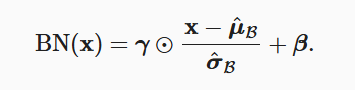
作用在全连接层和卷积层输出上,激活函数前面,全连接层和卷积层输入上,对于全连接层,作用在特征维,对于卷积层,作用在通道维。
最初论文是想用它来减少内部协变量转移,后续论文指出它可能就是通过在每个小批量里加入噪声来控制模型复杂度,因此没必要跟丢弃法混合使用
总结
- 固定小批量中的均值和方差,然后学习出适合的偏移和缩放
- 批量规范化有许多有益的副作用,主要是正则化
- Batch Normalization批量归一化方法可以加速神经网络的收敛,但一般不改变模型精度。仅在Batch中包含样本数量较多时有效。
- 对循环网络(RNN)或序列数据(Sequence)性能较差。
- 分布式运算时影响效率。
后续又提出了:
- Layer Normalization:在每一个样本特征空间内的归一化。
- Instance Normalization:在每一个样本特征空间内逐通道的归一化。
ResNet
学习ResNet首先要明白的就是残差块的概念:
- 串联一个层改变函数类,我们希望能扩大函数类
- 残差块加入快速通道来得到
f(x) = x + g(x)的结构

ResNet沿用了VGG完整的3×3卷积层设计。 残差块里首先有2个有相同输出通道数的3×3卷积层。 每个卷积层后接一个批量规范化层和ReLU激活函数。 然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。 这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。 如果想改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后再做相加运算。

每个模块有4个卷积层(不包括恒等映射的1×1卷积层)。 加上第一个7×7卷积层和最后一个全连接层,共有18层。 因此,这种模型通常被称为ResNet-18。 通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。 虽然ResNet的主体架构跟GoogLeNet类似,但ResNet架构更简单,修改也更方便。这些因素都导致了ResNet迅速被广泛使用。

来看看代码的实现:
1 | |