Tree
一、初识树
不同于之前学过的一般的一对一的结构,树是一种一对多的结构,树一个节点可能对应着一个节点或者好几个节点
(从书上嫖的定义:
树是n(n>=0)个结点的有限集。 当n = 0时,称为空树。在任意一棵非空树中应满足:
- 有且仅有一个特定的称为根的结点。
- 当n>1时,其余节点可分为m(m>0)个互不相交的有限集T1,T2,…,Tm,其中每个集合本身又是一棵树,并且称为根的子树。
二、 基本概念
1、节点的分类
结点拥有的子树数称为结点的度。度为0的结点称为叶结点(Leaf) 或终端结点;度不为0的结点称为非终端结点或分支结点。除根结点之外,分支结点也称为内部结点。树的度是树内各结点的度的最大值。

2、节点之间的关系
节点之间的称呼比较有意思,互相叫爸爸(bushi ,节点子树的根称为该节点的孩子,然后呢,孩子节点按照辈分要叫这个节点为爸爸,即父节点。同一个双亲节点之间互称兄弟。所以下图中 A节点是B、C的父节点,B、C是A节点的子节点,B、C之间互称兄弟节点。

3、树的层次
结点的层次从根开始算起,根为第一层,根的孩子为第二层 。树中结点的最大层次称为树
的深度或高度,下图中树的深度为4

三、树的抽象数据类型(ADT)

(书上摘的,记得下来自己看
四、树的存储结构
一般说起存储结构,就会想起前面学过的栈和队列,拥有两种存储结构,一种是顺序存储结构,一种还是顺序结构,另外一种是链式存储结构,但是树因为其较为复杂的机制,所以只使用顺序存储结构会很麻烦,因此树一般使用的是链式结构,主要有三种表示法用来表示树。以下表示法中的示例都是本树

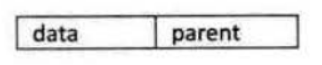
1. 双亲表示法
这种表示法中,每一个节点中专门设置一个域用来指示双亲的位置,如下图所示
1 | |
由此就可以推导出来上图中的M树的结构就如下图所示

思考:上图中的 -1 表示什么意思
这种表示法我们可以根据结点的 parent 指针很容易找到色的双亲结点,所用的时间复杂度为 O(1),但是如果想要知道孩子节点是哪一个则需要全部遍历完才行,比较麻烦
2.孩子表示法
把每个结点的孩子结点排列起来,以单链表作存储结构,则n个结点有n个孩子链表,如果是叶子结点则此单链表为空。然后n个头指针又组成一个线性表,采用顺序存储结构,存放进一个一维数组中,如图所示。
孩子表示法中需要两种结构,一种是孩子结点的结构,还有一种是表头结点
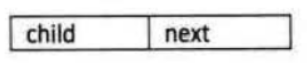
child保存数据,next是指针域,用于保存下一个结点的位置

同理,data用于保存数据,firstchild用于保存第一个孩子结点的位置
1 | |
3.孩子兄弟表示法
任意一棵树, 它的结点的第一个孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的。 因此,我们设置两个指针,分别指向该结点的第一个孩子和此结点的右兄弟
1 | |

(即生成一棵二叉树,至于怎么生成,后面会讲
五、二叉树
1、什么是二叉树
二叉树是另一种树形结构,其特点是每个结点至多只有两棵子树( 即二叉树中不存在度大于2的结点),并且二叉树的子树有左右之分,其次序不能任意颠倒。
与树相似,二叉树也以递归的形式定义。二叉树是n (n≥0) 个结点的有限集合:
2、二叉树的特点
- 每个结点最多有两棵子树,.注意不是只有两棵子树,而是最多有.没有子树或者有一棵子树都可以
- 左子树和右子树是有顺序的,次序不能任意颠倒。即使树中某结点只有一个子树,也要区分它是左子树还是右子树.

二叉树的5种基本形态

3、特殊的二叉树
3.1斜树
所有的结点都只有左子树的二叉树叫左斜树。所有结点都是只有右子树的二叉树叫右斜树。这两者统称为斜树。
3.2满二叉树
在一棵二叉树中,如果所有分支结点都存在左子树和右子树,并且所有叶子都同一层上,这样的二叉树称为满二叉树

3.3完全二叉树
对一棵具有n个结点的二叉树按层序编号,如果编号为 (l<i<n) 的结点与同样深度的满二叉树中编号为 i 的结点在二叉树中位置完全相同,则这棵二叉树称为完全二叉树

- 若i ≤ n / 2, 则结点i为分支结点,否则为叶子结点。
- 叶子结点只可能在层次最大的两层上出现。对于最大层次中的叶子结点,都依次排列在该层最左边的位置上。
- 若有度为1 的结点,则只可能有一个,且该结点只有左孩子而无右孩子(重要特征)。
- 按层序编号后,一旦出现某结点(编号为i)为叶子结点或只有左孩子,则编号大于i的结点均为叶子结点。
- 若n为奇数,则每个分支结点都有左孩子和右孩子;若n为偶数,则编号最大的分支结点(编号为n / 2 )只有左孩子,没有右孩子,其余分支结点左、右孩子都有。
注意:
完全二叉树和满二叉树的区别,满二叉树一定是棵完全二叉树,但完全二叉树不一定是满二叉树
4.二叉树的性质

- 非空二叉树上第i层上至多有 个结点(i 0)
- 高度为h的二叉树至多有 个结点(h 1)
- 任意一棵树,若结点数量为n,则边的数量为n − 1
- 非空二叉树上的叶子结点数(度为0的节点数)等于度为2的结点数加1,即
- 具有n个( n > 0 )结点的完全二叉树的高度为
- 对有n个结点的完全二叉树按从上到下、从左到右的顺序依次编号1 , 2… ∗ , n 则有以下关系:
- i = 1时,结点i是二叉树的根,没有双亲;若 i > 1结点i的双亲的编号为[i / 2]
- 当2i >n时,则结点 无左孩子(结点 为叶子结点) ;否则其左孩子是结点2i
- 如果 2i+1>n ,则结点 无右孩子;否则其右孩子是结点 2i+1
5.二叉树的存储结构
直接上链式结构、二叉树每个结点最多有两个孩子,所以为它设计一个数据域和两个指针域是比较自然的想法,我们称这样的链表叫做二叉链表。

1 | |

6.遍历二叉树
6.1 先序遍历
顺序为:根->左->右

1 | |
6.2 中序遍历
顺序:左->根->右

1 | |
6.3 后序遍历
顺序为:左->右->根

1 | |
6.4三种遍历的非递归算法
以下图这棵树为例
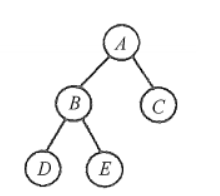
1. 中序遍历的非递归算法
1 | |
最后的遍历结果就是DBEAC
2. 先序遍历的非递归算法(和中序遍历是类似的
1 | |
最后的遍历结果就是ABDEC
3. 后序遍历的非递归算法
1 | |
最后的遍历结果就是DEBCA
6.5 层序遍历
故名思意,层序遍历就是按照每一层的顺序进行遍历,例如下图所示

1 | |
7.反推遍历结果
首先记住几个点:
- 由二叉树的先序序列和中序序列可以唯一地确定一棵二叉树。
- 由二叉树的后序序列和中序序列也可以唯一地确定一棵二叉树。
- 由二叉树的层序序列和中序序列也可以唯一地确定一棵二叉树。
- 只知道二叉树的先序序列和后序序列,则无法唯一确定一棵二叉树。
下面以这个序列作为演示
已知某一棵树的遍历结果如下图所示,请画出这棵树
前序遍历:ABCDEF
中序遍历:CBAEDF
分析:首先,根据前面所讲的前序和中序恶的遍历顺序,可以得知,A是该树的根节点,再结合中序遍历CB A EDF,可以得知,CB结点在根节点的左子树,EDF在根结点的右子树。由于先序先输出了B,所以B是A的孩子,而C是B的孩子,再根据中序中先输出了C,所以C是B的右孩子。右子树中根据先序遍历可得EF是D的子节点,再根据中序就可以确定E在左,D在右。即如下图所示的树。

8.创建二叉树
创建一棵二叉树和之前的遍历没有什么区别,唯一的不同就是多了内存分配。下面以先序遍历为例创建一棵二叉树

若想要创建如图所示的一棵二叉树,我们需要补全一下,这棵树的结构,把所有的结点都改成度为的结点,不够的就以符号‘#’补齐,以便让程序知道到了终点

补齐之后按照前序遍历的方式输入如下字符:AB###C##
1 | |
原理和之前的先序遍历是一样的,如果想使用中序遍历或者是后序遍历创建一棵树,只需要把递归代码的顺序改一下即可。
六、树、二叉树、森林的转换
1. 树转换为二叉树
- 加线。在所有兄弟结点之间加一条连线。
- 去钱。对树中每个结点,只保留它与第一个孩子结点的连线,删除与其他孩子结点之间的连线。
- 层次调整。以树的根结点为轴心,将整棵树顺时针旋转 定的角度,使之结构层次分明。注意第一个孩子是二叉树结点的左孩子,兄弟转换过来的孩子是结点的右孩子。


2. 森林转换为二叉树
- 把每个树转换为二叉树。
- 第一 棵二叉树不动,从第二棵二叉树开始,依次把后一棵 叉树的根结点作为
棵二叉树的根结点的右孩子,用线连接起来。当所有的二叉树连接起来后
就得到了由森林转换来的二叉树。



3. 二叉树转换为树
- 加线。若某结点的左孩子结点存在,则将这个左孩子的右孩子结点、右孩子的
- 右孩子结点、右孩子的右孩 的右孩子结点……将该结点与这些右孩子结点用线连接起来。
- 去钱。删除原二叉树中所有结点与其右孩子结点的连线。
- 层次调整使之结构层次分明。




4. 二叉树转换为森林
- 从根结点开始 若右孩子存在,则把与右孩子结点的连线 ,再查看分离后的二叉树,若右孩子存在,则连续去除……,直到所有右孩子连线都删除为止,得到分离的 叉树再将每棵分离后的 叉树转换为树即可(就是过程反一下而已



七、哈夫曼树
1. 带权路径长度及哈夫曼树的定义
树中结点常常被赋予一个表示某种意义的数值,称为该结点的权。从树的根到任意结点的路径长度(经过的边数)与该结点上权值的乘积,称为该结点的带权路径长度,树中所有叶结点的带权路径长度之和称为该树的带权路径长度。在含有n个带权叶结点的二叉树中,其中带权路径长度(WPL)最小的二叉树称为哈夫曼树,也称最优二叉树。 例如,下图中的3棵二叉树都有4个叶子结点a, b,c,d,分别带权7,5,2,4,它们的带权路径长度分别为

上图中C树的带权路径长度最小,因此为哈夫曼树
2. 构建一棵哈夫曼树
采用贪心算法的思想构造
- 先把有权值的叶子结点按照从大到小(从小到大也可以)的顺序排列成一个有序序列。
- 取最后两个最小权值的结点作为一个新节点的两个子结点,注意相对较小的是左孩子。
- 用第2步构造的新结点替掉它的两个子节点,插入有序序列中,保持从大到小排列。
- 重复步骤2到步骤3,直到根节点出现。

3. 哈夫曼编码
哈夫曼编码是一种被广泛应用而且非常有效的数据压缩编码
例如将这串字符用二进制转换
BADCADFEED
得到的代码如下图所示:

采用哈夫曼树进行编码,根据出现的次数确定权重。构造的哈夫曼树如下图所示:

然后转换为二进制代码:

和原来的相比,就会压缩了许多

哈夫曼树博大精深,这里只是粗浅的讲一下。
———————————————————————————————《完结撒花,感谢陪伴》